SKAMPI chez Martin
Table of Contents
Sitemap
|
|




Lecture d'articles
Lecture de la doc de SkaMPI. C'est un DSL facilement extensible. Curieusement les pt2pt demandent un certain nombre d'itérations alors que les collectives ont l'air de s'autotuner sur le nombre d'XP à faire. Il y a automatiquement un filtrage du nombre d'informations (par exemple, quand une collective implique beaucoup de processeurs, par défaut, il n'en laisse que 16 avec les plus gros, les plus petits). De même il y a un itérateur qui, s'il détecte des discontinuités va essayer de refaire des mesures là où ça a l'air de poser problème.
Le code est facilement extensible et il semble possible de court-circuiter les autotuning et de rajouter des itérateurs (pour avoir un échantillonnage aléatoire plutôt que parfaitement régulier par exemple…).
Les mécanismes d'auto-tunning mis en oeuvre dans skampi ou dans mpptest sont là pour essayer de détecter des anomalies de performance, des choses à améliorer dans la couche MPI.
- Reproducible Measurements of MPI Performance Characteristics par Bill Gropp: http://www.cs.uiuc.edu/~wgropp/bib/papers/1999/pvmmpi99/mpptest.pdf
- LogP: Towards a Realistic Model of Parallel Computation par David Culler, Richard Karp, David Patterson, Abhijit Sahay, Klaus Erik Schauser, Eunice Santos, Ramesh Subramonian, and Thorsten von Eicken http://www.cc.gatech.edu/~bader/COURSES/UNM/ece638-Fall2004/papers/CKP93.pdf
Fast Measurement of LogP Parameters for Message Passing Platforms Thilo Kielmann, Henri E. Bal, and Kees Verstoep http://www.cs.vu.nl/~kielmann/papers/rtspp00.pdf
r(m) = L + g (m) is the time at which the receiver has received the message.
When a sender transmits several messages in a row, the latency will contribute only once to the receiver completion time but the gap values of all messages sum up. This can be expressed as r(m1 ; m2 ;…; mn ) = L + g (m1)+ g (m2)+ … + g (mn).
La mesure du o_r se fait en attendant Delta (pour être sûr que le sender a bien envoyé le message) avant de faire la communication. Si jamais il y a un thread (ou l'OS) qui fait la communication avant, c'est mort… ou pas en fait. Après tout, si o, c'est le temps passé à faire de la recopie de buffers, c'est bon. Par contre, est-ce stable ?
Cette façon de mesurer les o_r oublie des cas. On ne sait pas bien ce qu'il se passe en cas de réceptions de plusieurs endroits. Le modèle est-il vraiment clair à ce sujet d'ailleurs ? Pas sûr car ça a été conçu pour faire du broadcast.
Le seul moment où il envoie n ping suivit d'un pong, c'est pour les messages de taille 0.
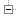
- Screenshots de Sweep3D qui m'ont conduit à repenser à LogP:
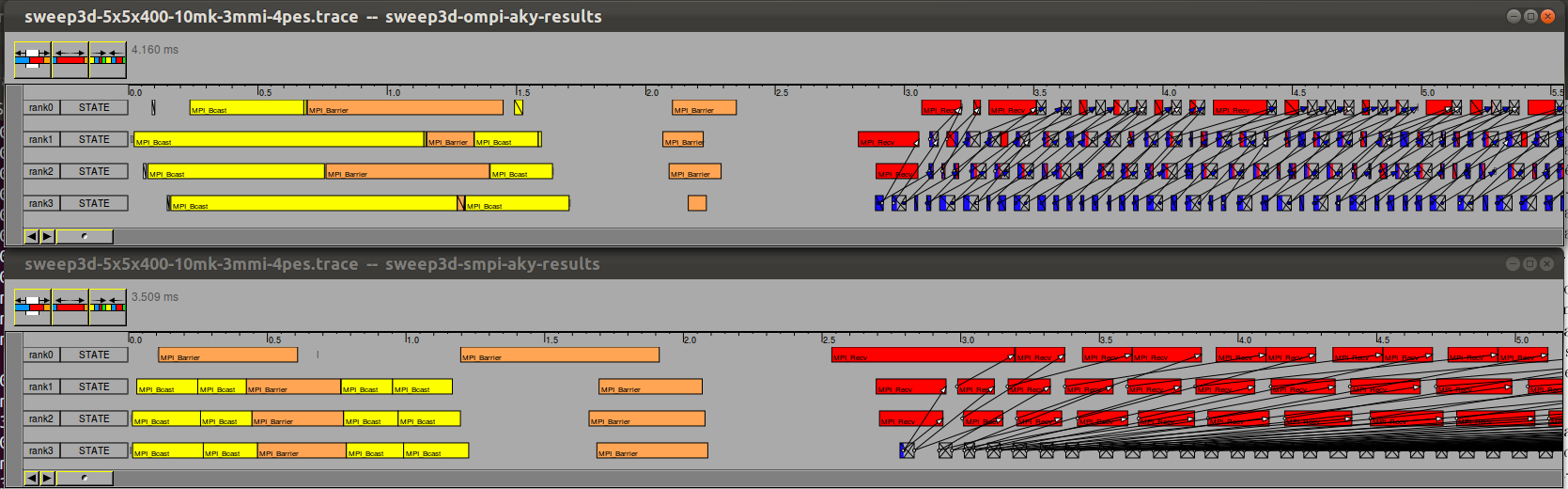
- Zomming a little:
Tests unitaires:
- L'asynchronisme ou le non-asynchronisme de MPI. MPI_ISend sleep(10s)
- Établir des expériences invalidantes de LogP
- recouvrement o / g
- Envoyer n sends in a row
- o est-il constant / stable
- Contention sur le lien entrant, sortant, interférences.
- si o < g (l'inverse étant considéré par Kielmann comme une anomalie, en particulier pour o_r), alors une série de send devrait conduire à un décalage de plus en plus important entre le sender et le receiver.
- il y a l'air d'y avoir un mode "eager" où l'envoi se fait de façon asynchrone et un mode où la communication ne se fait que quand le receiver est prêt. Comment le détecter?
Entered on